
Redis学习教程三:数据类型
发布: 更新时间:2022-09-09 14:05:01
Redis支持五种基本数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。三大特殊数据类型:geo(地理位置) hyperloglog(基数统计) bitmap(位图)以及新增的Stream消息队列
字符串类型(String)
key:value
常用操作:
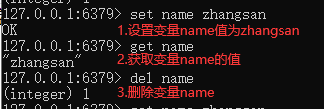
管理工具展示:
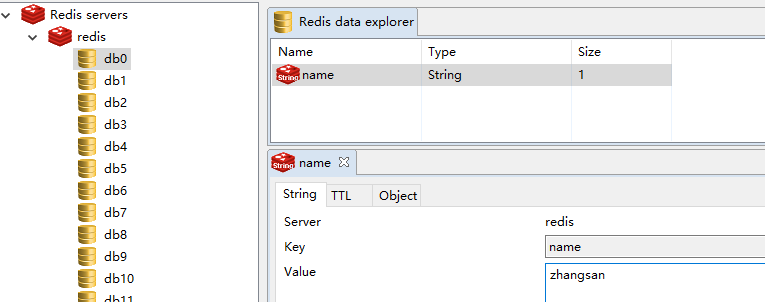
其它操作:
GETRANGE key start end #返回 key 中字符串值的子字符
GETSET key value #将给定 key 的值设为 value ,并返回 key 的旧值(old value)。
GETBIT key offset #对 key 所储存的字符串值,获取指定偏移量上的位(bit)。
MGET key1 [key2..] #获取所有(一个或多个)给定 key 的值。
SETBIT key offset value #对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit)。
SETEX key seconds value #将值 value 关联到 key ,并将 key 的过期时间设为 seconds (以秒为单位)。
SETNX key value #只有在 key 不存在时设置 key 的值。
SETRANGE key offset value #用 value 参数覆写给定 key 所储存的字符串值,从偏移量 offset 开始。
STRLEN key #返回 key 所储存的字符串值的长度。
MSET key value [key value ...] #同时设置一个或多个 key-value 对。
MSETNX key value [key value ...] #同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在。
PSETEX key milliseconds value #这个命令和 SETEX 命令相似,但它以毫秒为单位设置 key 的生存时间,而不是像 SETEX 命令那样,以
#秒为单位。
INCR key #将 key 中储存的数字值增一。
INCRBY key increment #将 key 所储存的值加上给定的增量值(increment) 。
INCRBYFLOAT key increment #将 key 所储存的值加上给定的浮点增量值(increment) 。
DECR key #将 key 中储存的数字值减一。
DECRBY key decrement #key 所储存的值减去给定的减量值(decrement) 。
APPEND key value #如果 key 已经存在并且是一个字符串, APPEND 命令将指定的 value 追加到该 key 原来值
#(value)的末尾。哈希类型(map格式)
key={filed:value,filed:value,filed:value,filed:value} 无序
常用操作:
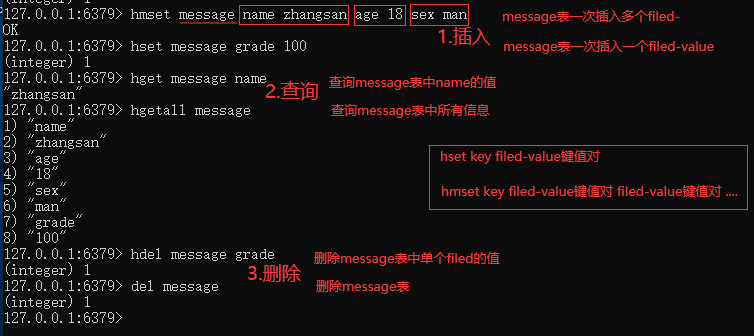
管理工具展示:
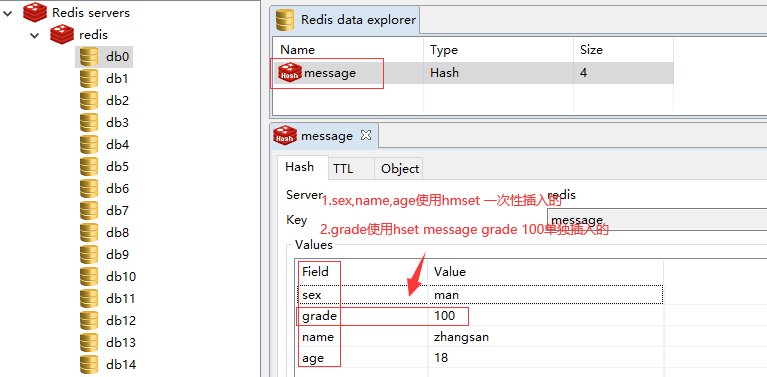
其它操作:
HEXISTS key field #查看哈希表 key 中,指定的字段是否存在。
HINCRBY key field increment #为哈希表 key 中的指定字段的整数值加上增量 increment 。
HINCRBYFLOAT key field increment #为哈希表 key 中的指定字段的浮点数值加上增量 increment 。
HKEYS key #获取所有哈希表中的字段
HLEN key #获取哈希表中字段的数量
HMGET key field1 [field2] #获取所有给定字段的值
HSETNX key field value #只有在字段 field 不存在时,设置哈希表字段的值。
HVALS key #获取哈希表中所有值。
HSCAN key cursor [MATCH pattern] #迭代哈希表中的键值对。
[COUNT count] 列表类型(list,linkedlist格式)
key=[value,value,value,value] 有序
常用操作:
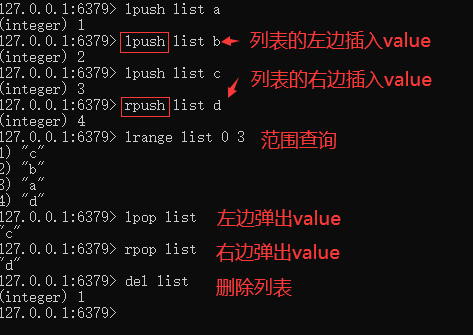
管理工具展示:
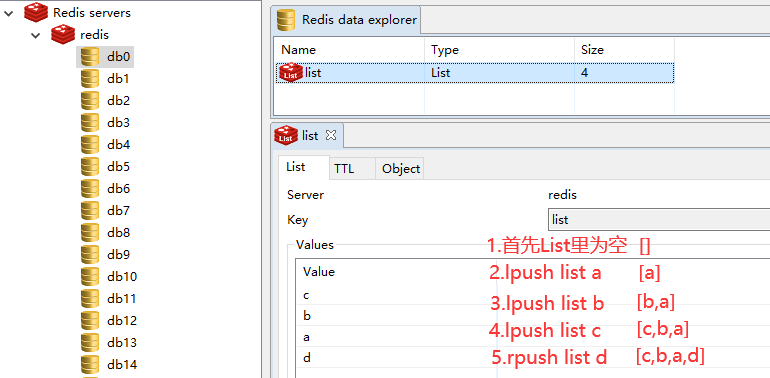
其它操作:
BLPOP key1 [key2 ] timeout #移出并获取列表的第一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
BRPOP key1 [key2 ] timeout #移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
BRPOPLPUSH source destination timeout #从列表中弹出一个值,将弹出的元素插入到另外一个列表中并返回它; 如果列表没有元素会阻塞列表直到等待
#超时或发现可弹出元素为止。timeout设置时间,单位ms
LINDEX key index #通过索引获取列表中的元素
LINSERT key BEFORE|AFTER pivot value #在列表的元素前或者后插入元素 pivot,在哪个元素前后插入的
LLEN key #获取列表长度
LPUSHX key value #将一个值插入到已存在的列表头部
LREM key count value #count > 0,从表头搜索,移除count个数;count<0,从表尾开始,删除|count|个;count=0,删除所有
LSET key index value #通过索引设置列表元素的值
LTRIM key start stop #对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。
RPOPLPUSH source destination #移除列表的最后一个元素,并将该元素添加到另一个列表并返回
RPUSHX key value #为已存在的列表添加值集合类型(set)
key =(value1,value2,value3) 无序去重
常用操作:

管理工具展示:
其它操作:
SADD key member1 [member2] #向集合添加一个或多个成员
SCARD key #获取集合的成员数
SDIFF key1 [key2] #返回第一个集合与其他集合之间的差异。
SDIFFSTORE destination key1 [key2] #返回给定所有集合的差集并存储在 destination 中
SINTER key1 [key2] #返回给定所有集合的交集
SINTERSTORE destination key1 [key2] #返回给定所有集合的交集并存储在 destination 中
SISMEMBER key member #判断 member 元素是否是集合 key 的成员
SMOVE source destination member #将 member 元素从 source 集合移动到 destination 集合
SPOP key #移除并返回集合中的一个随机元素
SRANDMEMBER key [count] #返回集合中一个或多个随机数
SREM key member1 [member2] #移除集合中一个或多个成员
SUNION key1 [key2] #返回所有给定集合的并集
SUNIONSTORE destination key1 [key2] #所有给定集合的并集存储在 destination 集合中
SSCAN key cursor [MATCH pattern] [COUNT count] #迭代集合中的元素有序集合类型(sortedset)
key=(value1,value2,value3) 有序去重
每个元素都会关联一个double类型的分数。redis正是通过分数来zset中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
常用操作:

管理工具展示:
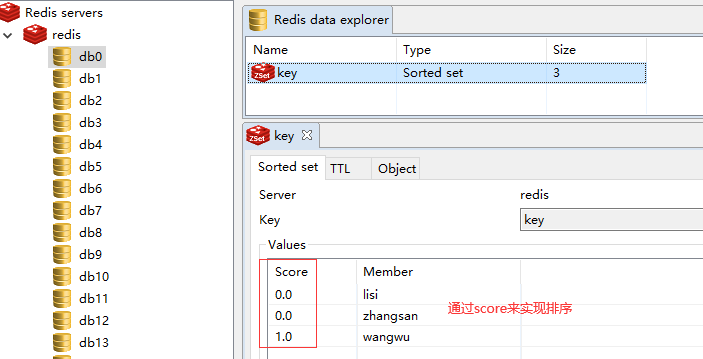
1.redis存储的是:key,value 格式的数据,其中Key都是字符串,value有5种不同的数据结构
2.列表类型支持重复元素
3.redis列表是简单的字符串列表,按照插入顺序排序,操作者可以添加一个元素到列表头部(左边)或者尾部(右边)
4.集合类型不允许重复元素
5.有序集合类型,不允许重复元素,且元素有顺序,每个元素都会关联一个double类型的分数,redis正是通过分数来为集合中的成员进行从小到大的排序。
其它操作:
ZCARD key #获取有序集合的成员数
ZCOUNT key min max #计算在有序集合中指定区间分数的成员数
ZINCRBY key increment member #有序集合中对指定成员的分数加上增量 increment
ZINTERSTORE destination numkeys key [key ...] #计算给定的一个或多个有序集的交集并将结果集存储在新的有序集合 destination 中
ZLEXCOUNT key min max #在有序集合中计算指定字典区间内成员数量
ZRANGE key start stop [WITHSCORES] #通过索引区间返回有序集合指定区间内的成员
ZRANGEBYLEX key min max [LIMIT offset count] #通过字典区间返回有序集合的成员
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT] #通过分数返回有序集合指定区间内的成员
ZRANK key member #返回有序集合中指定成员的索引
ZREM key member [member ...] #移除有序集合中的一个或多个成员
ZREMRANGEBYLEX key min max #移除有序集合中给定的字典区间的所有成员
ZREMRANGEBYRANK key start stop #移除有序集合中给定的排名区间的所有成员
ZREMRANGEBYSCORE key min max #移除有序集合中给定的分数区间的所有成员
ZREVRANGE key start stop [WITHSCORES] #返回有序集中指定区间内的成员,通过索引,分数从高到低
ZREVRANGEBYSCORE key max min [WITHSCORES] #返回有序集中指定分数区间内的成员,分数从高到低排序
ZREVRANK key member #返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序
ZSCORE key member #返回有序集中,成员的分数值
ZUNIONSTORE destination numkeys key [key ...] #计算给定的一个或多个有序集的并集,并存储在新的 key 中
ZSCAN key cursor [MATCH pattern] [COUNT count] #迭代有序集合中的元素(包括元素成员和元素分值)地理位置信息GEO
该功能在 Redis 3.2 版本新增。
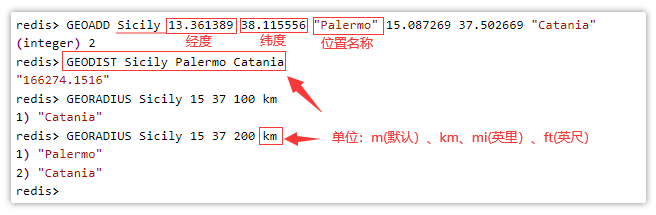
- geoadd:添加地理位置的坐标。
- geopos:获取地理位置的坐标。
- geodist:计算两个位置之间的距离。
- georadius:根据用户给定的经纬度坐标来获取指定范围内的地理位置集合。
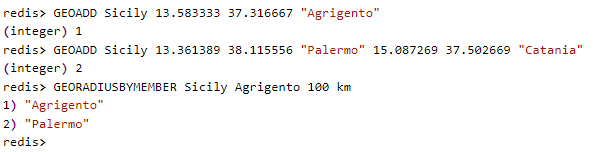
- georadiusbymember:根据储存在位置集合里面的某个地点获取指定范围内的地理位置集合。
- geohash:返回一个或多个位置对象的 geohash 值。
georadiusbymember实例:
geohash实例

基数统计HyperLogLog
该功能在 Redis 2.8.9 版本新增
什么是基数?
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
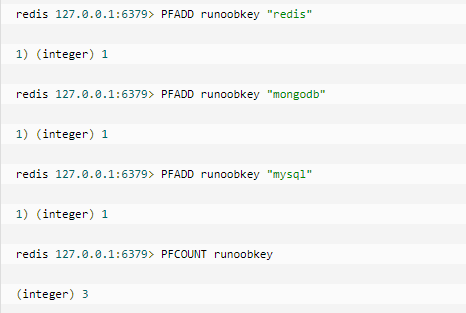
PFADD key element [element ...] #添加指定元素到 HyperLogLog 中。
PFCOUNT key [key ...] #返回给定 HyperLogLog 的基数估算值。
PFMERGE destkey sourcekey [sourcekey ...] #将多个 HyperLogLog 合并为一个 HyperLogLog位图Bitmap
1、什么是bitmap?
bitmap也叫位图,也就是用一个bit位来表示一个东西的状态,我们都知道bit位是二进制,所以只有两种状态,0和1。
2、为什么要有bitmap?
bitmap的出现就是为了大数据量而来的,但是前提是统计的这个大数据量每个的状态只能有两种,因为每一个bit位只能表示两种状态。
下面我们直接以一个统计亿级用户活动的状态来说明吧。
3、案例说明
案例描述:
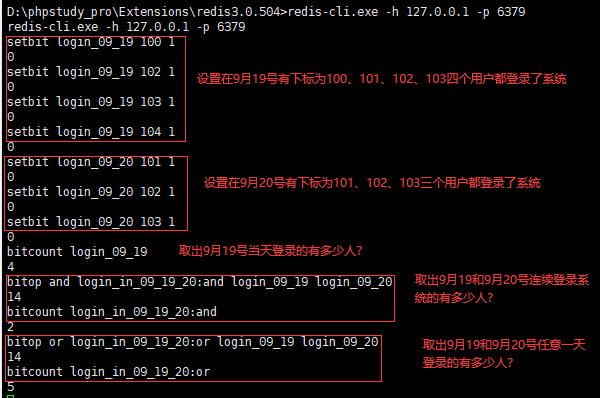
如果有一个上亿用户的系统,需要我们去统计每一天的用户登录情况,我们应该如何去解决?
前提条件:设置在9月19号有下标为100、101、102、103四个用户都登录了系统
设置在9月20号有下标为100、101、102三个用户都登录了系统
提出问题:
1、取出9月19号登录系统的有多少人?
答:直接获取即可。
2、取出9月19号和9月20号连续登录系统的有多少人?
答:两天的数据取&运算。
3、取出9月19号与9月20号任意一天登录的有多少人?
答:两天的数据取|运算。
解决方案
3.2.1、解决方案1—使用传统数据库解决
如果我们需要使用传统的数据库去统计的话,我么需要创建一张表,然后某个用户登录了,我们就去在表里面插上一条记录,登记用户的id,用户登录的时间等等,但是这样出现的问题就是,每一天的数据量都很大,我们在统计日活时,效率就很低,所以这种解决方案是不能被考虑的。
3.2.2、解决方案2—使用bitmap解决
既然用户登录只有两种状态,那么,我们就可以用bitmap
比如0表示未登录,1表示登录
消息队列Stream
该功能在Redis 5.0 版本新增加的数据结构。
Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。
简单来说发布订阅 (pub/sub) 可以分发消息,但无法记录历史消息。
而 Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
Redis Stream 的结构如下所示,它有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容:
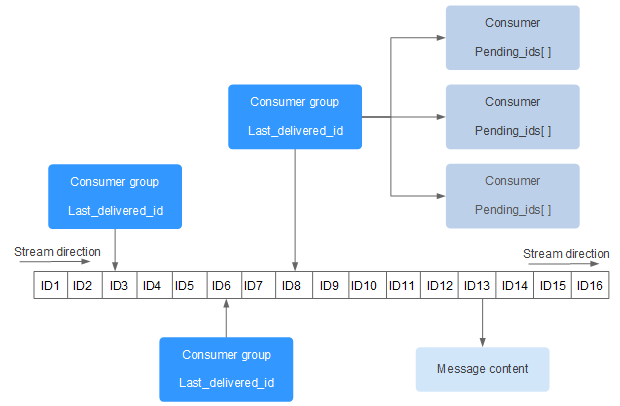
- Consumer Group :消费组,使用 XGROUP CREATE 命令创建,一个消费组有多个消费者(Consumer)。
- last_delivered_id :游标,每个消费组会有个游标 last_delivered_id,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。
- pending_ids :消费者(Consumer)的状态变量,作用是维护消费者的未确认的 id。 pending_ids 记录了当前已经被客户端读取的消息,但是还没有 ack (Acknowledge character:确认字符)。
1.消息队列相关命令
#大写的是关键字,命令必须要有的,如下面的ID COUNT BLOCK STREAMS MAXLEN
XADD key ID field value [field value ...] #使用 XADD 向队列添加消息,如果指定的队列不存在,则创建一个队列。消息 id,我们使用 * 表示
#由 redis 生成,可以自定义,但是要自己保证递增性。
XTRIM key MAXLEN [~] count #对流进行修剪,限制长度
XDEL key ID [ID ...] #删除消息
XLEN key #获取流包含的元素数量,即消息长度
XRANGE key start end [COUNT count] #获取消息列表,会自动过滤已经删除的消息(-最小值,+最大值)
XREVRANGE key end start [COUNT count] #反向获取消息列表,会自动过滤已经删除的消息
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...] #以阻塞或非阻塞方式获取消息列表 
2.消费者组相关命令:
XGROUP [CREATE key groupname id-or-$] [SETID key groupname id-or-$] [DESTROY key groupname] [DELCONSUMER key groupname consumername] #创建消费者组,$ : 表示从尾部开始消费,只接受新消息,当前 Stream 消息会全部忽略。
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
#读取消费组中的消息-
1
原神3.8心海武器推荐 原神3.8心海带什么武器
-
2
阴阳师寻迹骰怎么获得 阴阳师寻迹骰获得方法
-
3
王者荣耀妄想都市观光怎么获得 王者荣耀妄想都市观光活动
-
4
阴阳师新召唤屋和幕间皮肤效果怎么样 阴阳师新召唤屋和幕间皮肤获取方法介绍
-
5
羊了个羊7.26攻略 羊了个羊7月26日怎么过
-
6
崩坏星穹铁道求不得成就攻略介绍 崩坏星穹铁道求不得成就怎么获得
-
7
崩坏星穹铁道去吧阿刃成就攻略介绍 崩坏星穹铁道去吧阿刃成就怎么获得
-
8
时空中的绘旅人罗夏生日有什么复刻 绘旅人罗夏生日礼包复刻一览
-
9
银河境界线武器强度怎么看 银河境界线武器强度排行攻略
-
10
阴阳师红蛋蛋限时福利怎么获得 阴阳师再结前缘版本福利介绍









