
Python爬虫教程七:Scrapy框架(上)
发布: 更新时间:2022-10-14 22:11:51
一、Scrapy框架简介
Scrapy是用Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
框架的优势在于,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
pip install scrapy
二、运行原理
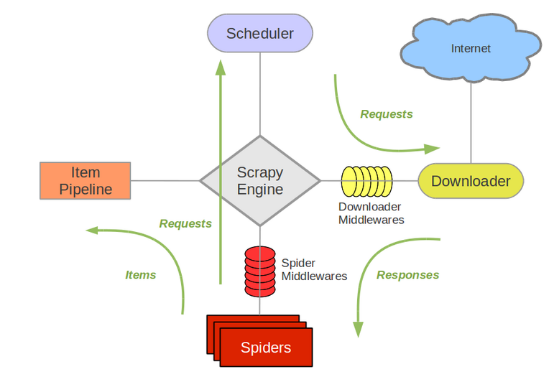
Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载8):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
三. 使用操作步骤
制作 Scrapy 爬虫 一共需要以下几步:
- 选择目标网站
- 定义要抓取的数据(通过Scrapy Items来完成的)
- 编写提取数据的spider
- 执行spider,获取数据
- 数据存储
第一步、创建一个scrapy项目
scrapy startproject mySpider
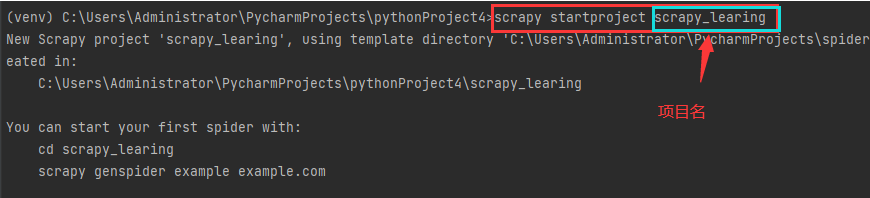
第二步、生成一个spider
scrapy genspider picSpider loutoushe.com

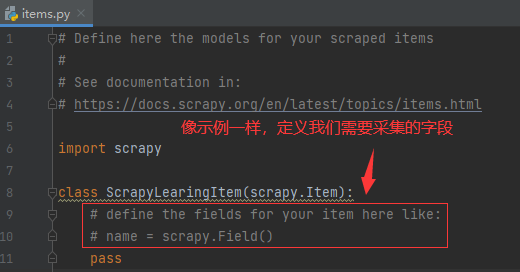
第三步、items文件中定义采集字段
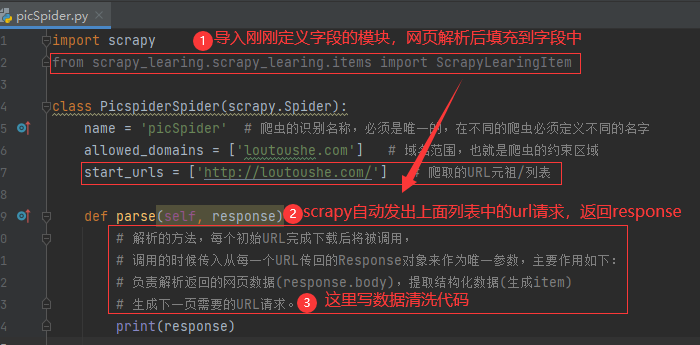
第四步、提取数据
第五步、保存数据
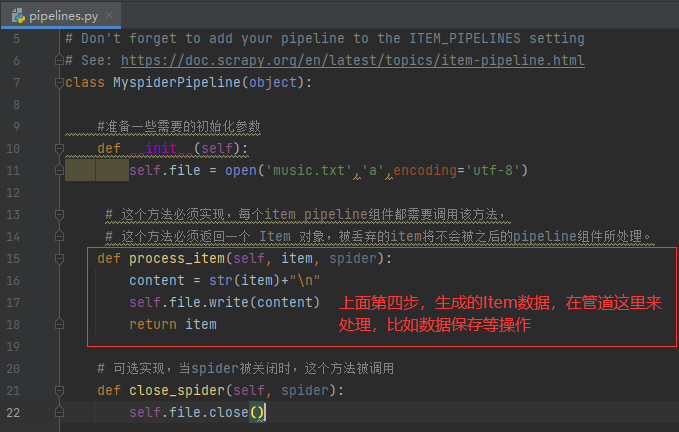
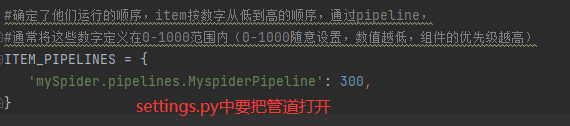
第六步、程序运行
# 在命令行中运行爬虫
scrapy crawl qb # qb爬虫的名字
# 在pycharm中运行爬虫
from scrapy import cmdline
cmdline.execute("scrapy crawl qb".split())四、项目结构
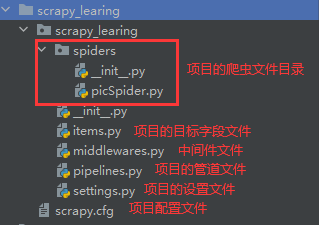
五、scrapy命令行
| 命令 | 英文 | 翻译 |
|---|---|---|
| bench | Run quick benchmark test | 运行快速基准测试 |
| fetch | Fetch a URL using the Scrapy downloader | 使用Scrapy下载程序获取URL |
| edit | Edit spider | 编辑爬虫 |
| genspider | Generate new spider using pre-defined templates | 使用预定义的模板生成新的spider |
| parse | Parse URL (using its spider) and print the results | 解析URL并打印结果 |
| runspider | Run a self-contained spider (without creating a project) | 运行一个自包含的爬行器(不创建项目) |
| crawl | Run a spider | 运行一个爬虫 |
| list | List available spiders | 列出可用的爬虫 |
| settings | Get settings values | 获取设置值 |
| shell | Interactive scraping console | 交互式控制台 |
| startproject | Create new project | 创建新项目 |
| version | Print Scrapy version | 打印Scrapy版本 |
| view | Open URL in browser, as seen by Scrapy | 在浏览器中打开URL,就像Scrapy看到的那样 |
-
1
原神3.8心海武器推荐 原神3.8心海带什么武器
-
2
阴阳师寻迹骰怎么获得 阴阳师寻迹骰获得方法
-
3
王者荣耀妄想都市观光怎么获得 王者荣耀妄想都市观光活动
-
4
阴阳师新召唤屋和幕间皮肤效果怎么样 阴阳师新召唤屋和幕间皮肤获取方法介绍
-
5
羊了个羊7.26攻略 羊了个羊7月26日怎么过
-
6
崩坏星穹铁道求不得成就攻略介绍 崩坏星穹铁道求不得成就怎么获得
-
7
崩坏星穹铁道去吧阿刃成就攻略介绍 崩坏星穹铁道去吧阿刃成就怎么获得
-
8
时空中的绘旅人罗夏生日有什么复刻 绘旅人罗夏生日礼包复刻一览
-
9
银河境界线武器强度怎么看 银河境界线武器强度排行攻略
-
10
阴阳师红蛋蛋限时福利怎么获得 阴阳师再结前缘版本福利介绍









