
基于scrapy的redis安装和配置方法
发布: 更新时间:2022-11-13 15:52:10
在定向爬虫的制作过程中,使用分布式爬取技术可以显著提高爬取效率。而 Redis 配合 Scrapy 是实现分布式爬取的基础。
Redis 是一个高性能的 Key-Value 数据库,它把数据保存在内存里。因此可以有非常快的数据读写速度。
一、安装连接包
安装python连接包:scrapy-redis
pip install scrapy-redis二、redis服务安装配置
推荐版本:stable 3.0.2,具体安装教程看下面文章,更多redis教程可以站内搜索!
[postsbox post_id="2596"]
三、开启redis服务
redis-server redis.conf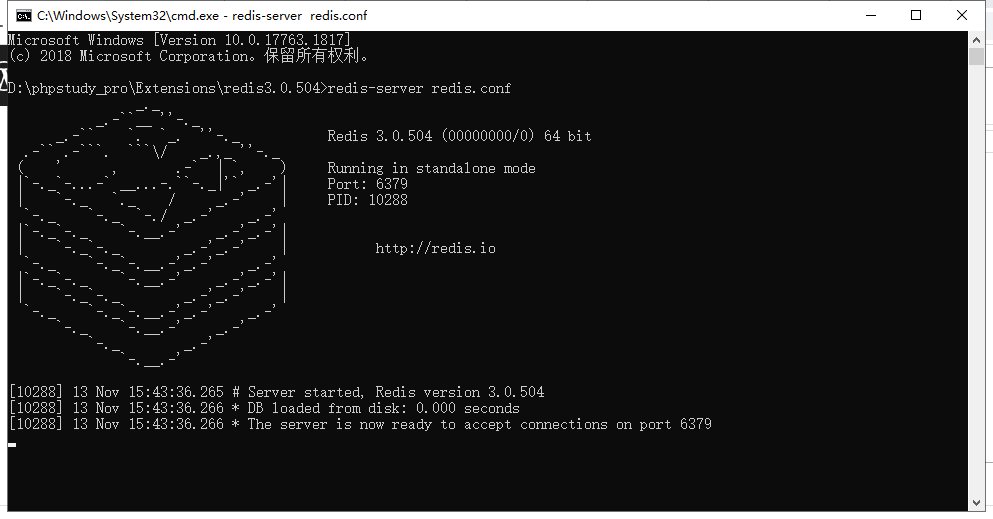
同样的可以使用redis-cli命令,进行客户端操作,比如:清除缓存
redis-cli flushdb # 清除缓存四、scrapy中使用redis
1.settings.py配置redis
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'
REDIS_URL = None # 一般情况可以省去
REDIS_HOST = '127.0.0.1' # 也可以根据情况改成 localhost
REDIS_PORT = 6379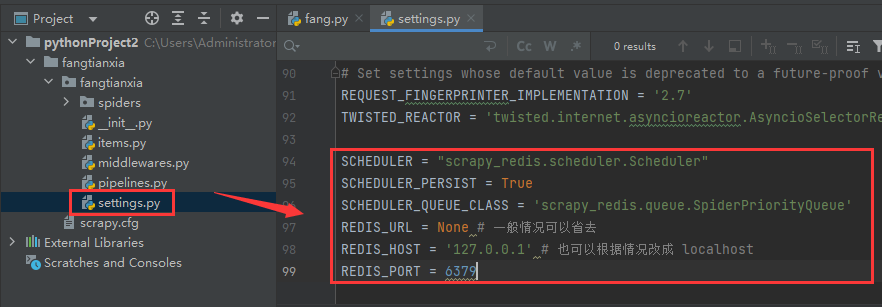
2.在scrapy中使用scrapy-redis
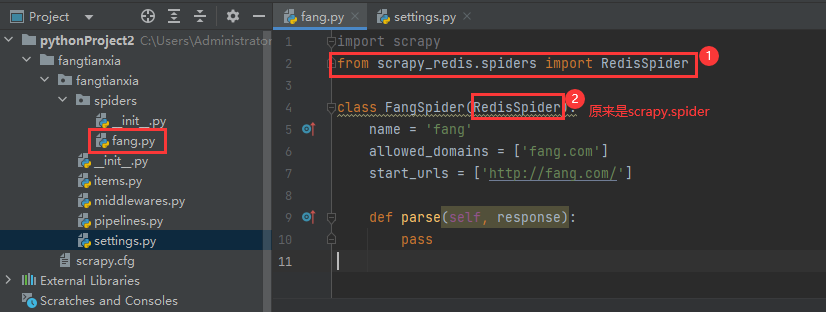
文章排行
-
1
原神3.8心海武器推荐 原神3.8心海带什么武器
-
2
阴阳师寻迹骰怎么获得 阴阳师寻迹骰获得方法
-
3
王者荣耀妄想都市观光怎么获得 王者荣耀妄想都市观光活动
-
4
阴阳师新召唤屋和幕间皮肤效果怎么样 阴阳师新召唤屋和幕间皮肤获取方法介绍
-
5
羊了个羊7.26攻略 羊了个羊7月26日怎么过
-
6
崩坏星穹铁道求不得成就攻略介绍 崩坏星穹铁道求不得成就怎么获得
-
7
崩坏星穹铁道去吧阿刃成就攻略介绍 崩坏星穹铁道去吧阿刃成就怎么获得
-
8
时空中的绘旅人罗夏生日有什么复刻 绘旅人罗夏生日礼包复刻一览
-
9
银河境界线武器强度怎么看 银河境界线武器强度排行攻略
-
10
阴阳师红蛋蛋限时福利怎么获得 阴阳师再结前缘版本福利介绍









