
shell编程快速入门九:字符截取、替换和处理命令
发布: 更新时间:2023-02-16 02:10:27
一、正则表达式
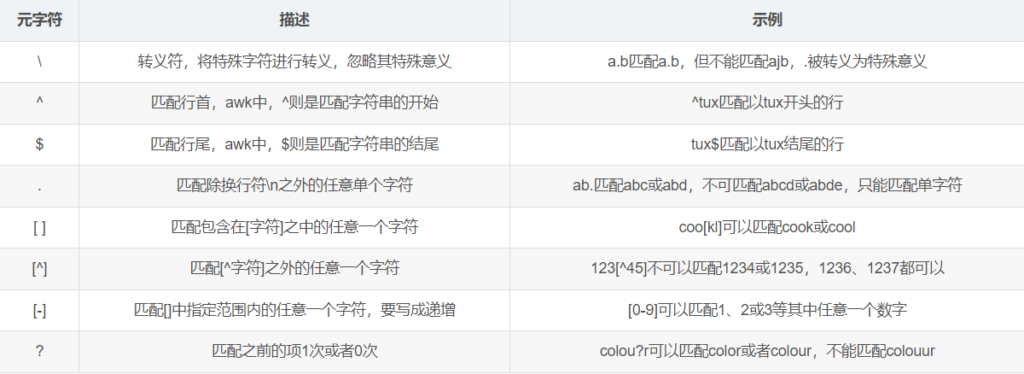
更多的可以参考这篇文章:https://www.jb51.net/tools/shell_regex.html
1.正则表达式与通配符
- 正则表达式是用在文件中匹配符合条件的字符串,正则是包含匹配,
grep,awk,sed等命令可以支持正则表达式 - 通配符是用来匹配符合条件的文件名,通配符是完全匹配,ls,find,cp这些命令不支持正则表达式,所以只能用Shell自己的通配符来进行匹配了。
2.正则与grep的使用
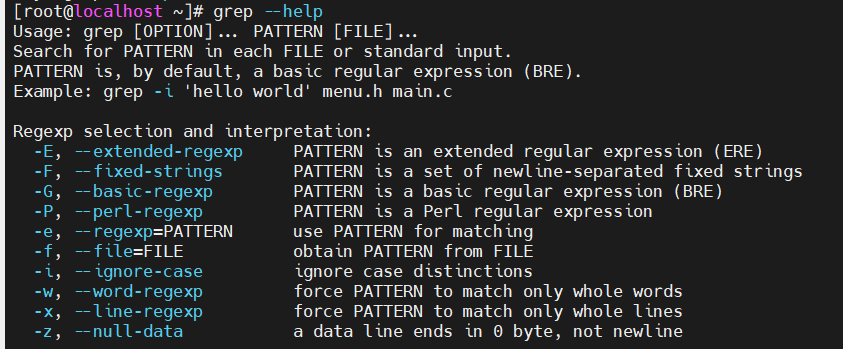
示例1:

示例2:

二、字符截取、替换命令
1.cut 列提取命令
[root@localhost ~]$ cut [选项] 文件名
选项:
-f 列号: 提取第几列
-d 分隔符: 按照指定分隔符分割列
-n 取消分割多字节字符
-c 字符范围: 不依赖分隔符来区分列,而是通过字符范围(行首为0)来进行字段提取。“n-”表示从第n个字符到行尾;“n-m”从第n个字符到第m个字符;“一m”表示从第1个字符到第m个字符。
--complement 补足被选择的字节、字符或字段
--out-delimiter 指定输出内容是的字段分割符cut命令的默认分隔符是制表符,也就是“tab”键,不过对空格符可是支持的不怎么好啊
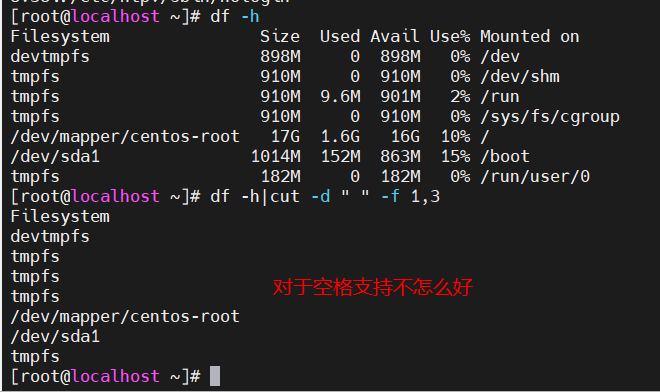
1)提取多列,只要列号直接用“,”分开,如下:
cut -f 2,3 /etc/passwd
2)按照字符进行提取。8-代表第8个字符到最后,8-20代表第8到20个字符,而“-8”代表从行首到第八个字符
cut -c 8- /etc/passwd
2.awk编程
内容有点多,详情见下面文章!
3.sed 文本选取、替换、删除、新增的命令
内容有点多,详情见下面文章!
三、字符处理命令
1. sort 排序命令
[root@localhost~]$ sort [选项] 文件名
选项:
-f: 忽略大小写
-b: 忽略每行前面的空白部分
-n: 以数值型进行排序,默认使用字符串型排序
-r: 反向排序
-u: 删除重复行。就是uniq命令
-t: 指定分隔符,默认是分隔符是制表符
-k n[,m]: ―按照指定的字段范围排序。从第n字段开始,m字段结束(默认到行尾)示例:
sort命令默认是用每行开头第一个字符来进行排序的,比如:
[root@localhost~]$ sort /etc/passwd
#排序用户信息文件
如果想要反向排序,请使用“-r”选项:
[root@localhost~]$ sort -r/etc/passwd
#反向排序
如果想要指定排序的字段,需要使用“-t”选项指定分隔符,并使用“-k”选项指定字段号。假如我想要按照UID字段排序/etc/passwd文件:
[root@localhost~]$ sort -t ":" -k 3,3 /etc/passwd
#指定分隔符是“:”,用第三字段开头,第三字段结尾排序,就是只用第三字段排序
因为sort默认是按照字符排序,前面用户的UID的第一个字符都是1,所以这么排序。要想按照数字排序,请使用“-n”选项:
[root@localhost~]$ sort -n -t ":" -k 3,3 /etc/passwd当然“-k”选项可以直接使用“-k 3”,代表从第三字段到行尾都排序(第一个字符先排序,如果一致,第二个字符再排序,知道行尾)。
2.uniq 取消重复行
[root@localhost~]$ uniq [选项] 文件名
选项:
-i:忽略大小写
3.wc 统计命令
[root@localhost~]$ wc [选项] 文件名
选项:
-l:只统计行数
-w:只统计单词数
-m:只统计字符数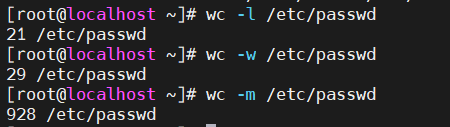
-
1
原神3.8心海武器推荐 原神3.8心海带什么武器
-
2
阴阳师寻迹骰怎么获得 阴阳师寻迹骰获得方法
-
3
王者荣耀妄想都市观光怎么获得 王者荣耀妄想都市观光活动
-
4
阴阳师新召唤屋和幕间皮肤效果怎么样 阴阳师新召唤屋和幕间皮肤获取方法介绍
-
5
羊了个羊7.26攻略 羊了个羊7月26日怎么过
-
6
崩坏星穹铁道求不得成就攻略介绍 崩坏星穹铁道求不得成就怎么获得
-
7
崩坏星穹铁道去吧阿刃成就攻略介绍 崩坏星穹铁道去吧阿刃成就怎么获得
-
8
时空中的绘旅人罗夏生日有什么复刻 绘旅人罗夏生日礼包复刻一览
-
9
银河境界线武器强度怎么看 银河境界线武器强度排行攻略
-
10
阴阳师红蛋蛋限时福利怎么获得 阴阳师再结前缘版本福利介绍









