
Python爬虫教程五:数据清洗 - BeautifulSoup模块
发布: 更新时间:2022-10-14 12:44:46
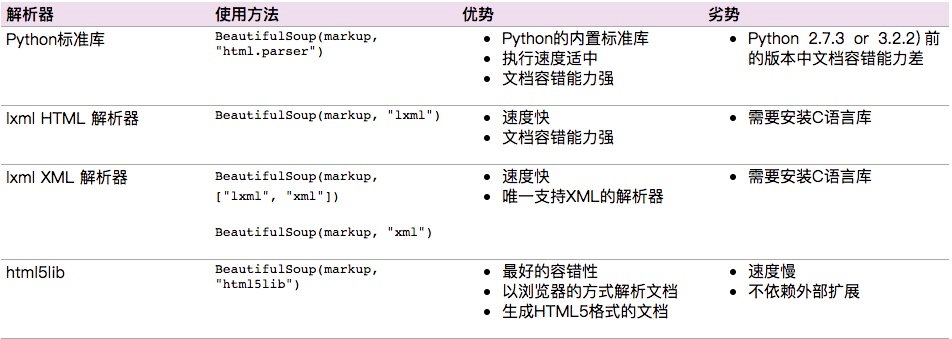
和lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据
区别在于:
一、安装
- 安装 Beautiful Soup
- pip 安装:
pip install beautifulsoup4
- pip 安装:
- 安装解析器:
lxml 解析器:pip install lxmlhtml5lib 解析器:pip install html5lib
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装。
二、实例化BeautifulSoup对象
通过解析器,实例化BeautifulSoup对象,文章这里取变量名为soup。
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
# 方法一:解析字符串形式的html
soup=BeautifulSoup(html,"lxml")
print(type(soup))
# 方法二:解析本地html文件
# soup2=BeautifulSoup(open("index.html"))
# 格式化输出soup对象
print(soup.prettify())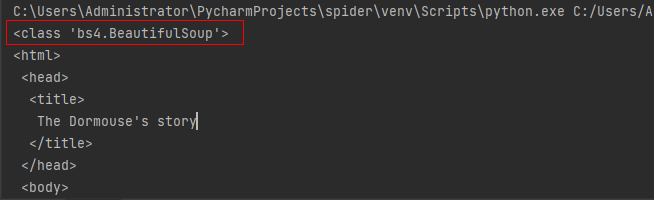
三、基本使用
1.标签选择器
在快速使用中我们添加如下代码:
print(soup.title)
print(type(soup.title))
print(soup.head)
print(soup.p)
通过这种soup.标签名 我们就可以获得这个标签的内容,这里有个问题需要注意,通过这种方式获取标签,如果文档中有多个这样的标签,返回的结果是第一个标签的内容,如上面我们通过soup.p获取p标签,而文档中有多个p标签,但是只返回了第一个p标签内容
2.获取名称
当我们通过soup.title.name的时候就可以获得该title标签的名称,即title
3.获取属性
print(soup.p.attrs['name'])
print(soup.p['name'])
上面两种方式都可以获取p标签的name属性值
4.获取内容
print(soup.p.string)
结果就可以获取第一个p标签的内容:
The Dormouse's story
5.嵌套选择
我们直接可以通过下面嵌套的方式获取
print(soup.head.title.string)
6.家族节点
子孙节点
soup.标签名.contents:结果是将p标签下的所有直接子标签存入到了一个列表中
soup.标签名.children:作用跟contents一样,但是是返回一个可迭代对象,而不是一个列表
soup.标签名.descendants:获取所有后代节点,包含孙子节点
父节点和祖先节点
soup.标签名.parent:获取父节点的信息
list(enumerate(soup.标签名.parents)):可以获取祖先节点,这个方法返回的结果是一个列表,会分别将a标签的父节点的信息存放到列表中,以及父节点的父节点也放到列表中,并且最后还会讲整个文档放到列表中,所有列表的最后一个元素以及倒数第二个元素都是存的整个文档的信息
兄弟节点
soup.a.next_siblings 获取后面的兄弟节点
soup.a.previous_siblings 获取前面的兄弟节点
soup.a.next_sibling 获取下一个兄弟标签
souo.a.previous_sinbling 获取上一个兄弟标签
四、标准选择器
find_all()
soup.find_all(name,attrs,recursive,text,**kwargs)
可以根据标签名,属性,内容查找文档
#根据字符串查找所有的a标签,返回一个结果集,里面装的是标签对象
data=soup.find_all("a")
#根据正则表达式查找标签
data2=soup.find_all(re.compile("^b"))
#根据属性查找标签
data3=soup.find_all(id="link2") #特殊的标签属性可以不写attrs,例如id,class,name等
data32=soup.find_all(attrs={'id': 'list-1'}))
#根据标签内容获取标签内容
data4=soup.find_all(text="Lacie")
data5=soup.find_all(text=["Lacie","Tillie"])
data6=soup.find_all(text=re.compile("Do"))find()
soup.find(name,attrs,recursive,text,**kwargs)
find返回的匹配结果的第一个元素
其他一些类似的用法:
find_parents()返回所有祖先节点,find_parent()返回直接父节点。
find_next_siblings()返回后面所有兄弟节点,find_next_sibling()返回后面第一个兄弟节点。
find_previous_siblings()返回前面所有兄弟节点,find_previous_sibling()返回前面第一个兄弟节点。
find_all_next()返回节点后所有符合条件的节点, find_next()返回第一个符合条件的节点
find_all_previous()返回节点后所有符合条件的节点, find_previous()返回第一个符合条件的节点
五、CSS选择器
通过select()直接传入CSS选择器就可以完成选择
熟悉前端的人对CSS可能更加了解,其实用法也是一样的
#CSS选择器类型:标签选择器、类选择器、id选择器
#通过标签名查找
data1=soup.select("a")
#通过类名查找
data2=soup.select(".sister")
#通过id查找
data3=soup.select("#link2")
#组合查找
data4=soup.select("p #link1")
#通过其他属性查找
data5=soup.select('a[href="http://example.com/tillie"]')1.获取内容
通过get_text()就可以获取文本内容
2.获取属性
或者属性的时候可以通过[属性名]或者attrs[属性名]
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml') #htl为字符串格式html
for ul in soup.select('ul'):
print(ul['id'])
print(ul.attrs['id'])-
1
原神3.8心海武器推荐 原神3.8心海带什么武器
-
2
阴阳师寻迹骰怎么获得 阴阳师寻迹骰获得方法
-
3
王者荣耀妄想都市观光怎么获得 王者荣耀妄想都市观光活动
-
4
阴阳师新召唤屋和幕间皮肤效果怎么样 阴阳师新召唤屋和幕间皮肤获取方法介绍
-
5
羊了个羊7.26攻略 羊了个羊7月26日怎么过
-
6
崩坏星穹铁道求不得成就攻略介绍 崩坏星穹铁道求不得成就怎么获得
-
7
崩坏星穹铁道去吧阿刃成就攻略介绍 崩坏星穹铁道去吧阿刃成就怎么获得
-
8
时空中的绘旅人罗夏生日有什么复刻 绘旅人罗夏生日礼包复刻一览
-
9
银河境界线武器强度怎么看 银河境界线武器强度排行攻略
-
10
阴阳师红蛋蛋限时福利怎么获得 阴阳师再结前缘版本福利介绍









