
Python爬虫教程六:多线程爬虫案例实例
发布: 更新时间:2022-10-14 17:47:46
一、python多线程
关于多线程的知识,看下面这篇文章即可。
[postsbox post_id="3777"]
二、多线程实例
这里我们是把本站python爬虫教程四中的爬虫例子,给改编写成使用多线程的模式的。
原代码效果如下:
import os
import requests
from lxml import etree
# https://loutoushe.com/page/366 1-366页
class Spider:
def __init__(self,begin,end):
self.beginPage=begin
self.endPage=end
self.url="https://loutoushe.com/page/"
self.BASE_DIR = "C:/Users/Administrator/Desktop/Pic/"
# 构造url
def beauty_girl_Spider(self):
for page in range(self.beginPage,self.endPage+1):
pageUrl=self.url+str(page)
self.load_page(pageUrl)
# 爬取页面文章链接
def load_page(self,pageUrl):
res = requests.get(pageUrl)
# 将获取到的str类型结果,转为Html类型,再通过xpath找出要的连接
html = etree.HTML(res.text)
links = html.xpath('//div[@class="post-inner"]/div/a/@href')
for i in links:
self.load_detial_page(i)
# 爬取帖子详情页,获得图片的链接
def load_detial_page(self,detail_pageUrl):
detail = requests.get(detail_pageUrl)
detail_html = etree.HTML(detail.text)
title = detail_html.xpath("//title")[0].text
pictures = detail_html.xpath('//div[@class="swiper-slide"]/img/@data-src')
#创建图片集的名字创建相应的目录
dirctory = self.BASE_DIR + title
os.mkdir(dirctory)
#遍历图片链接,下载图片
num=len(pictures)
for i in range(num):
print(f"正在下载{title},第{i+1}张.....")
self.load_picture(dirctory, pictures[i])
# 通过图片所在链接,爬取图片并保存图片到本地:
def load_picture(self,dictory, pic_link):
pic_name = pic_link.split('/')[-1]
path = f"{dictory}/{pic_name}" # 保存地址
pic = requests.get(pic_link)
file = open(path, "wb")
file.write(pic.content) # 下载图片
if __name__ == '__main__':
spider=Spider(5,6) #实例化图片爬虫对象,爬第5到第6页
spider.beauty_girl_Spider()![图片[2] - Python爬虫教程四:数据清洗-xpath表达式 - 三酷猫](https://www.sankumao.com/wp-content/uploads/2022/10/2022101313360362.png)
# beauty_girl_Spider() 构造url
# load_page() 爬取页面文章链接
# load_detial_page() 爬取文章详情页,获得图片的链接
# load_picture() 通过图片所在链接,爬取图片并保存图片到本地
整体思路:
- 四个方法解耦合。通过队列的方法共享数据(队列自带锁的特性)
- 构造3类线程:爬取页面文章链接线程、爬取图片链接线程、下载图片线程
- 其中,下载图片是最耗时的线程,所以使用线程池里多给他几个。
代码展示:
import os
import requests
from lxml import etree # 网页解析
import threading # 线程
import queue # 队列
import re #去掉标题特殊符号
from concurrent.futures import ThreadPoolExecutor # 线程池
from requests.packages import urllib3 # ssl证书问题
urllib3.disable_warnings()
# 构造url,这个简单,不用专门开线程去做这个事情。
url = "https://loutoushe.com/page/"
BASE_DIR = "C:/Users/Administrator/Desktop/Pic/"
url_list=[] # 构造的pageUrl放到数组中。
def beauty_girl_Spider(beginPage,endPage,listQueue):
for page in range(beginPage,endPage+1):
pageUrl=url+str(page)
listQueue.put(pageUrl) #数据存放在队列里,供其它进程使用
# 爬取页面文章链接,一个线程去爬取文章的Url
def load_page(listQueue,pageQueue):
while not flag1:
pageUrl=listQueue.get()
print(f"启动采集文章页URL线程,当前列表url为:{pageUrl}")
res = requests.get(pageUrl)
# 将获取到的str类型结果,转为Html类型,再通过xpath找出要的连接
html = etree.HTML(res.text)
links = html.xpath('//div[@class="post-inner"]/div/a/@href')
for i in links:
pageQueue.put(i) #数据存放在队列里,供其它进程使用
# 爬取帖子详情页,获得图片的链接,一个线程去爬取一篇文章的图片的Url
def load_detial_page(pageQueue,dataQueue):
while not flag2:
detail_pageUrl=pageQueue.get()
print(f"启动采集图片URL线程,当前文章url为:{detail_pageUrl}")
detail = requests.get(detail_pageUrl)
detail_html = etree.HTML(detail.text)
title = detail_html.xpath("//title")[0].text
title_re=re.sub(r'[/:*?"<>|\\]| - 路透社', '', title) #去除特殊字符,不然目录创建不了
pictures = detail_html.xpath('//div[@class="swiper-slide"]/img/@data-src')
#创建图片集的名字创建相应的目录
dirctory = BASE_DIR + title_re
os.mkdir(dirctory)
#遍历图片链接,下载图片
for i in pictures:
dataQueue.put((dirctory,i)) #数据存放在队列里,供其它进程使用
# 通过图片所在链接,爬取图片并保存图片到本地:一个线程去下载图片
def load_picture(dataQueue):
while not flag3:
dictory=dataQueue.get()[0]
pic_link=dataQueue.get()[1]
print(f"启动下载图片URL线程,当前图片url为:{pic_link}")
pic_name = pic_link.split('/')[-1]
path = f"{dictory}/{pic_name}" # 保存地址
pic = requests.get(pic_link,verify=False)
# 下载图片
file = open(path, "wb")
file.write(pic.content)
file.close()
flag1=False #判断列表url队列是否为空
flag2=False #判断文章url队列是否为空
flag3=False #判断数据队列中是否为空
def main():
# 列表url队列
listQueue=queue.Queue()
beauty_girl_Spider(9,10,listQueue)
# 文章url队列
pageQueue = queue.Queue()
#存放采集结果的数据队列
dataQueue=queue.Queue()
#启动线程,利用线程池,这里我下载图片开了20个线程
threadpool = ThreadPoolExecutor(22)
threadpool.submit(load_page, listQueue,pageQueue)
threadpool.submit(load_detial_page, pageQueue, dataQueue)
for i in range(20):
threadpool.submit(load_picture,dataQueue)
# 当listQueue为空时,结束采集列表线程
while not listQueue.empty():
pass
global flag1
flag1 = True
#当pageQueue为空时,结束采集文章页线程
while not pageQueue.empty():
pass
global flag2
flag2=True
#当dataQueue为空时,结束下载线程
while not dataQueue.empty():
pass
global flag3
flag3=True
print("等待线程池中的任务执行完毕中······")
threadpool.shutdown(True) # 等待线程池中的任务执行完毕后,在继续执行
print("结束!")
if __name__ == '__main__':
main()
效果展示
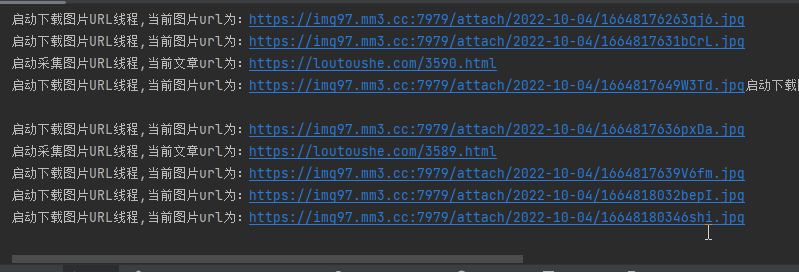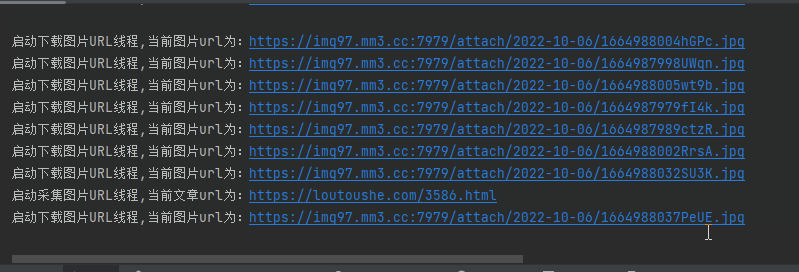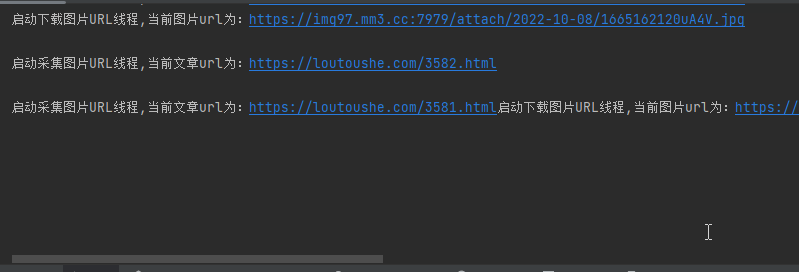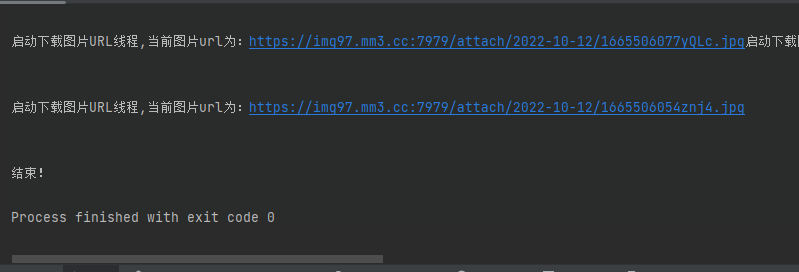
这下载速度杠杠的滴!几百张图片不到一分钟就下载完啦!
标签:python, 多线程, 爬虫, 爬虫案例
文章排行
-
1
原神3.8心海武器推荐 原神3.8心海带什么武器
-
2
阴阳师寻迹骰怎么获得 阴阳师寻迹骰获得方法
-
3
王者荣耀妄想都市观光怎么获得 王者荣耀妄想都市观光活动
-
4
阴阳师新召唤屋和幕间皮肤效果怎么样 阴阳师新召唤屋和幕间皮肤获取方法介绍
-
5
羊了个羊7.26攻略 羊了个羊7月26日怎么过
-
6
崩坏星穹铁道求不得成就攻略介绍 崩坏星穹铁道求不得成就怎么获得
-
7
崩坏星穹铁道去吧阿刃成就攻略介绍 崩坏星穹铁道去吧阿刃成就怎么获得
-
8
时空中的绘旅人罗夏生日有什么复刻 绘旅人罗夏生日礼包复刻一览
-
9
银河境界线武器强度怎么看 银河境界线武器强度排行攻略
-
10
阴阳师红蛋蛋限时福利怎么获得 阴阳师再结前缘版本福利介绍









